Metodo Monte Carlo

Questa voce o sezione sugli argomenti Fisica e matematica è priva o carente di note e riferimenti bibliografici puntuali.

Il metodo Monte Carlo è un'ampia classe di metodi computazionali basati sul campionamento casuale per ottenere risultati numerici. Può essere utile per superare i problemi computazionali legati ai test esatti (ad esempio i metodi basati sulla distribuzione binomiale e calcolo combinatorio, che per grandi campioni generano un numero di permutazioni eccessivo).
Il metodo è usato per trarre stime attraverso simulazioni. Si basa su un algoritmo che genera una serie di numeri tra loro non correlati, che seguono la distribuzione di probabilità che si suppone abbia il fenomeno da indagare. La non correlazione tra i numeri è assicurata da un test chi quadrato.
La simulazione Monte Carlo calcola una serie di realizzazioni possibili del fenomeno in esame, con il peso proprio della probabilità di tale evenienza, cercando di esplorare in modo denso tutto lo spazio dei parametri del fenomeno. Una volta calcolato questo campione casuale, la simulazione esegue delle 'misure' delle grandezze di interesse su tale campione. La simulazione Monte Carlo è ben eseguita se il valore medio di queste misure sulle realizzazioni del sistema converge al valore vero.
Le sue origini risalgono alla metà degli anni 40 nell'ambito del Progetto Manhattan. I formalizzatori del metodo sono Enrico Fermi, John von Neumann e Stanisław Marcin Ulam[1]. Il nome Monte Carlo fu inventato in seguito da Nicholas Constantine Metropolis riferendosi al noto casinò. L'uso di tecniche basate sulla selezione di numeri casuali era già citato in un lavoro di Lord Kelvin del 1901 ed in alcuni studi di William Sealy Gosset[1].
L'algoritmo Monte Carlo è un metodo numerico utilizzato per trovare le soluzioni di problemi matematici a molte variabili e che non possono essere risolti facilmente, per esempio il calcolo integrale. L'efficienza di questo metodo aumenta rispetto agli altri metodi quando la dimensione del problema cresce.
Un primo esempio di utilizzo del metodo Monte Carlo è rappresentato dall'esperimento dell'ago di Buffon; il suo più famoso utilizzo fu quello di Enrico Fermi, che nel 1930 usò un metodo casuale per problemi di trasporto neutronico[1].
Descrizione generale

Non c'è un solo metodo Monte Carlo; il termine descrive una classe di approcci utilizzati per una larga categoria di problemi. Tuttavia, questi approcci tendono a seguire un particolare schema:
- Definire un dominio di possibili dati in input.
- Generare input casuali dal dominio con una certa distribuzione di probabilità determinate.
- Eseguire un calcolo deterministico utilizzando i dati in ingresso (input).
- Aggregare i risultati dei calcoli singoli nel risultato finale.
Integrazione
I metodi deterministici di integrazione numerica operano considerando un numero di campioni uniformemente distribuiti. In generale questo metodo lavora molto bene per funzioni di una variabile. Tuttavia, per funzioni di vettori, i metodi deterministici di quadratura possono essere inefficienti. Per integrare numericamente una funzione di un vettore bidimensionale sono richieste griglie di punti equispaziati sulla superficie stessa. Per esempio una griglia di 10x10 richiede 100 punti. Se il vettore è a 100 dimensioni, la stessa spaziatura sulla griglia dovrebbe richiedere 10100 punti – troppo dispendioso computazionalmente. Le 100 dimensioni non hanno un significato irragionevole, poiché in molti problemi di fisica, una "dimensione" è equivalente a un grado di libertà.
I metodi di Monte Carlo forniscono una soluzione a questo problema di crescita del numero di gradi di libertà. Finché la funzione in questione ha un buon comportamento, può essere valutata selezionando in modo casuale i punti in uno spazio 100-dimensionale, e prendendo alcune tipologie di medie dei valori della funzione in questi punti. Per il teorema del limite centrale, questo metodo mostrerà ordine di convergenza ; per esempio quadruplicando il numero dei punti equispaziati si dimezza l'errore, nonostante il numero delle dimensioni.

Una caratteristica di questo metodo è quella di scegliere i punti in modo casuale, ma vengono scelti con maggior probabilità i punti che appartengono alle regioni che contribuiscono maggiormente al calcolo dell'integrale rispetto a quelli che appartengono a regioni di basso contributo. In altre parole, i punti dovrebbero essere scelti secondo una distribuzione simile in forma alla funzione integranda. Comprensibilmente, fare ciò è difficile tanto quanto risolvere l'integrale, ma ci sono altri metodi di approssimazione possibili, a partire da quelli che costruiscono una funzione integrabile simile a quella da integrare, fino ad arrivare ad una delle procedure adattive.
Un simile approccio implica l'uso di low-discrepancy sequences piuttosto del metodo quasi-Monte Carlo. I metodi Quasi-Monte Carlo spesso possono essere più efficienti come metodi di integrazione numerica poiché la successione di valori generata riempie meglio l'area e le successive valutazioni possono far convergere più velocemente la simulazione alla soluzione.
Discussione analitica
Per un modello stocastico sia θ la quantità da determinarsi. Si esegua una simulazione, generando la variabile casuale in modo che θ sia il valore atteso di Consideriamo una seconda simulazione, generando una variabile casuale tale che il suo valore atteso sia sempre θ. Proseguiamo con simulazioni, generando fino a variabili casuali con Come stimatore di θ possiamo prendere la media aritmetica delle variabili casuali generate, cioè





![{\displaystyle E[X_{k}]=\theta .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fbb43a5bb20cb6d7a37a36622c813643c9e2fc40)

in quanto Qual è il valore più appropriato di ? Supponiamo di avere variabili aleatorie indipendenti, aventi la stessa distribuzione. Sia σ2 la varianza della variabile e θ il valore atteso, ossia
![{\displaystyle E[X]=\theta .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ca04563b82aed8fde092f3835b026d8fcb5082b9)



![{\displaystyle E[X_{i}]=\theta ,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/185a3802d5eac8e5a68ac0920d20377f6ba174a1)

La media campionaria viene definita da


Il suo valore atteso è:
![{\displaystyle E[X]={\frac {\sum _{i=1}^{n}E[X_{i}]}{n}}=\theta .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81b44abd29eee90d56dd0710ac63cf75e90317bf)
Quindi è uno stimatore non distorto (cioè con valore atteso uguale a quello del parametro) di θ. La sua varianza, usando la formula di Bienaymé è:
![{\displaystyle \operatorname {Var} (X)=E{\bigl [}(X-\theta )^{2}{\bigr ]}=\operatorname {Var} \left[{\frac {\sum _{i=1}^{n}X_{i}}{n}}\right]={\frac {\sum _{i=1}^{n}\operatorname {Var} (X_{i})}{n^{2}}}={\frac {\sigma ^{2}}{n}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/14e85d8d28ea3316e418a876c6d50b4da107ac47)
Pertanto è una variabile aleatoria con media θ e varianza ne segue che è uno stimatore efficiente quando è piccolo. Fissata una tolleranza per ed avendo stimato si può in tal modo stimare





Si può imporre che il valore atteso ottenuto con lo stimatore stia dentro un ben definito intervallo di confidenza. Si può a tale scopo utilizzare una conseguenza del teorema del limite centrale. Sia una successione di variabili casuali indipendenti e distribuite identicamente aventi la media finita μ e la varianza finita σ2. Allora


dove è la funzione di distribuzione di una variabile casuale normale standard,


Quando il teorema del limite centrale ci dice che la variabile


è approssimativamente distribuita come una variabile aleatoria normale unitaria, indicata con cioè con media zero e varianza 1. Sia ora dove quel numero tale che, per una variabile normale unitaria, si abbia




Allora, dal teorema del limite centrale si ha che, asintoticamente per grande

che afferma che la probabilità che la media θ sia compresa nell'intervallo
![{\displaystyle \left[X-z\left({\frac {\alpha }{2}}\right){\frac {\sigma }{\sqrt {n}}},X+z\left({\frac {\alpha }{2}}\right){\frac {\sigma }{\sqrt {n}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6c69b8bc229921baaadc71a286377d69a9d79fb4)
è (1 - α). Perciò, assegnato 1-α e conoscendo σ, si può stimare il minimo valore di necessario.
Nasce quindi il problema di come stimare la varianza σ2 = E[(X - θ)2].
Definizione. La varianza del campione S2 è definita da

Vale il seguente risultato.
Proposizione. E[S2]= σ2 Infatti si ha:

ne segue
![{\displaystyle (n-1)E[S^{2}]=E\left[\sum _{i=1}^{n}X_{i}^{2}\right]-nE[X^{2}]=nE[X_{i}^{2}]-nE[X^{2}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d80afd597a396f335ae17e2a9bd3ef901ae4a6d)
Per una variabile aleatoria si ha:
![{\displaystyle E[Y^{2}]=\operatorname {Var} (Y)+{{\bigl (}E[Y]{\bigr )}}^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/05f8fe5bbc01e5e00a634327b329f2939379431d)
e quindi
![{\displaystyle E[X_{i}^{2}]=\operatorname {Var} (X_{i})+{{\bigl (}E[X_{i}]{\bigr )}}^{2}=\sigma ^{2}+\theta ^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5374957d73c1a706ea494332022566e6b2f793a4)
Inoltre
![{\displaystyle E[X^{2}]=\operatorname {Var} (X)+{{\bigl (}E[X]{\bigr )}}^{2}={\frac {\sigma ^{2}}{n}}+\theta ^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/046042d716fc718c1590396a100a7ede99479d16)
Ne segue
![{\displaystyle (n-1)E[S^{2}]=n\sigma ^{2}+n\theta ^{2}-\sigma ^{2}-n\theta ^{2}=(n-1)\sigma ^{2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1a3d5ea9c2d4cceb8f5541b61f4899d87dca017f)
Supponiamo ora di avere variabili aleatorie indipendenti aventi la stessa funzione di distribuzione F e di volere stimare il parametro θ(F) (per evidenziare che tale quantità deve essere calcolata rispetto alla funzione di distribuzione F). Sia lo stimatore proposto per θ(F); se questo non corrisponde al valore medio, il metodo precedentemente esposto per stimare la varianza dello stimatore non si può applicare. Vediamo come si può stimare l'errore quadratico medio che si commette quando si usa questo stimatore:


![{\displaystyle EQM(F)=E_{F}\!\left[{{\bigl (}g(X_{1},X_{2},\dots ,X_{n})-\theta (F){\bigr )}}^{2}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f30b624eddd9daec3b4f98e3ba7f2fb80f155234)
dove il pedice F significa che il valore d'aspettazione viene calcolato rispetto alla funzione di distribuzione F che per il momento è incognita.
Un metodo per stimare tale quantità è quello del bootstrap, utilizzando la funzione di distribuzione empirica Fe(x) definita da:

La legge forte dei grandi numeri afferma che per n molto grande, con probabilità 1, Fe(x) tende a F(x). Allora un valore approssimato di EQM(F) è dato da (approssimazione di bootstrap):
![{\displaystyle EQM(F)=E_{Fe}\!\left[{{\bigl (}g(X_{1},X_{2},\ldots ,X_{n})-\theta (F_{e}){\bigr )}}^{2}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b0821f5589dc7bba3269bbe2cbe5292a7b0cc523)
Va rilevato, da un punto di vista operativo, che il dimensionamento della simulazione si supera facilmente grazie alla crescente disponibilità di potenza di calcolo. In altre parole, procedendo all'uso del metodo su calcolatore, sarà sufficiente generare una serie di prove di ampiezza sicuramente ridondante per assicurarsi la significatività della stima.
Esempi
Rendimento di un titolo
Si voglia stimare il rendimento mensile di un titolo azionario. Il titolo esiste da cinque anni, quindi si hanno a disposizione solo 60 rendimenti mensili. Supponiamo che i rendimenti si distribuiscano seguendo una variabile casuale normale.
Calcoliamo:
- Media campionaria;
- Scarto quadratico medio campionario, su base giornaliera (che poi si adatterà con la formula della radice quadrata del tempo al periodo mensile).
Con un modello di regressione lineare cercheremo di stimare la media a un mese. Successivamente, si andranno a generare attraverso l'algoritmo Monte Carlo una serie di medie "sperimentali" che saranno ricavate da una distribuzione normale (perché si è ipotizzato che i rendimenti seguano questa distribuzione) con media pari alla media stimata e scarto quadratico medio pari allo scarto quadratico medio campionario a un mese.
Una strategia per procedere e stimare la vera media del fenomeno, a questo punto, può essere quella di ricavare la media generale di tutte le medie sperimentali ottenute. I dati ottenuti forniscono stime tanto migliori quanto maggiore è il numero delle prove fatte.
Determinazione del valore π
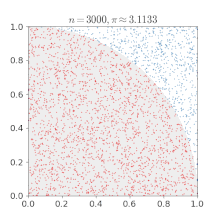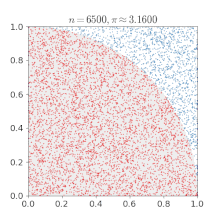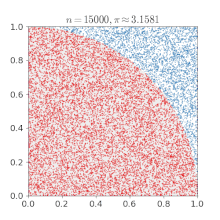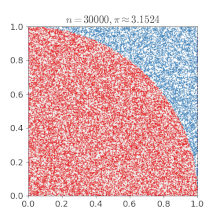
Sia un punto di coordinate con e e scegliamo casualmente i valori di e






Se allora il punto appartiene al settore di disco (un quarto del cerchio a cui appartiene) di centro di raggio 1.


L'area del settore di disco è il raggio elevato al quadrato per diviso 4. Nell'esempio il raggio è uguale a uno e quindi l'area di interesse è Il punto può cadere quindi o nel quarto di cerchio o nel quadrato circoscritto al settore di disco. La probabilità che il punto cada all'interno del settore di disco è quindi uguale al rapporto tra l'area del settore e l'area del quadrato circoscritto al settore di disco che è uguale a 1; quindi la probabilità è




Facendo il rapporto del numero dei punti che cadono nel settore di disco con il numero dei tiri effettuati si ottiene un'approssimazione del numero se il numero dei tiri è grande.
Eseguendo numericamente l'esempio si ottiene un andamento percentuale dell'errore mostrato nel grafico sottostante.

Determinazione della superficie di un lago
Questo è un esempio classico della divulgazione del metodo Monte-Carlo. Sia data una zona rettangolare o quadrata di cui la lunghezza dei lati è conosciuta. Al centro di quest'area si trova un lago la cui superficie è sconosciuta. Grazie alle misure dei lati della zona, si conosce l'area del rettangolo. Per determinare l'area del lago, si chiede ad una truppa armata di tirare colpi di cannone in modo aleatorio su questa zona. Contiamo in seguito il numero N di palle che sono restate sulla terra, possiamo quindi determinare il numero di palle che sono cadute dentro il lago: È sufficiente quindi stabilire un rapporto tra i valori:



Per esempio, se il terreno ha superficie di 1000 m2, e supponiamo che l'armata tiri 500 palle e che 100 proiettili sono caduti dentro il lago allora la superficie del lago è di: 100*1000/500 = 200 m2.

Naturalmente, la qualità della stima migliora aumentando il numero dei tiri ed assicurandosi che l'artiglieria non miri sempre lo stesso posto ma copra bene la zona. Questa ultima ipotesi coincide con l'ipotesi di avere un buon generatore di numeri aleatori, questa condizione è indispensabile per avere dei buoni risultati con il metodo Monte Carlo. Un generatore distorto è un po' come un cannone il cui tiro tende a indirizzarsi verso alcune zone rispetto ad altre: le informazioni che se ne possono ricavare sono anch'esse distorte.
Alcune applicazioni
Il metodo è molto usato in varie discipline. Tra le possibili applicazioni: fisica statistica e ingegneria, dove si presta molto bene a risolvere problemi legati, ad esempio, alla fluidodinamica; in economia e finanza per prezzare i derivati e le opzioni non standard; in ottica, per simulare l'illuminazione naturale; in fisica medica trova uso per la pianificazione di trattamenti radioterapeutici, in particolare nella protonterapia a pencil beam; nella chimica computazionale il Monte Carlo quantistico è un metodo per la determinazione della struttura elettronica; ecc…
È molto potente se usato in combinazione con altri metodi non parametrici come il resampling.
Un altro esempio particolare dell'utilizzo del Metodo Monte Carlo è l'impiego del metodo nell'analisi scacchistica. Negli ultimi anni alcuni programmi scacchistici in commercio implementano delle opzioni d'analisi che utilizzano "Monte Carlo analisi". Per valutare una posizione, si fanno giocare al computer migliaia di partite partendo dalla posizione da analizzare, facendo eseguire al PC delle mosse "random" (una scelta casuale tra le mosse che il programma giudica più logiche). La media dei risultati ottenuti in queste partite è un'indicazione plausibile della mossa migliore.[2]
Il metodo Monte Carlo trova un'applicazione di successo ancora maggiore nel gioco del go. In tal caso l'applicazione del metodo è ancora più diretta: molti programmi raggiungono un buon livello di gioco senza aver bisogno di restringere la selezione casuale a un sottoinsieme di mosse legali determinato da una funzione di valutazione (esempio di programma che usa questo metodo in unione con il machine learning è AlphaGo).
Note
Bibliografia
- W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications, Biometrika, 1970, pp. 97-109.
- Bernd A. Berg, Markov Chain Monte Carlo Simulations and Their Statistical Analysis (With Web-Based Fortran Code), World Scientific 2004, ISBN 981-238-935-0.
- P. Kevin MacKeown, Stochastic Simulation in Physics, 1997, ISBN 981-3083-26-3
- Harvey Gould & Jan Tobochnik, An Introduction to Computer Simulation Methods, Part 2, Applications to Physical Systems, 1988, ISBN 0-201-16504-X
- C.P. Robert and G. Casella. "Monte Carlo Statistical Methods" (second edition). New York: Springer-Verlag, 2004, ISBN 0-387-21239-6
- Makers of commercial packages which implement Monte Carlo algorithms in include Palisade Corporation (@Risk), Decisioneering (Crystal Ball) and Vanguard Software (DecisionPro)
- Mosegaard, Klaus., eTarantola, Albert, 1995. Monte Carlo sampling of solutions to inverse problems. J. Geophys. Res., 100, B7, 12431-12447.
- Albert Tarantola, Inverse Problem Theory, Society for Industrial and Applied Mathematics, 2005, ISBN 0-89871-572-5.
- Morin, L. Richard, Monte Carlo Simulation in the Radiological Sciences, CRC Press, ISBN 0-8493-5559-1.
- Arnold Kaufmann, La fabbricazione artificiale del caso; il metodo di Monte Carlo, in Le tecniche decisionali. Introduzione alla Praxeologia, traduzione di Giampaolo Barosso, Milano, il Saggiatore, 1968, SBN IT\ICCU\SBL\0076985.
Voci correlate
- Algoritmo di Metropolis-Hastings
- FERMIAC
- FLUKA
- MNCP
- Geant4
- Metodo Monte Carlo Dinamico
- Tissue simulation toolkit
- AlphaGo
Altri progetti
Altri progetti
- Wikibooks
- Wikimedia Commons
 Wikibooks contiene implementazioni del metodo Monte Carlo
Wikibooks contiene implementazioni del metodo Monte Carlo Wikimedia Commons contiene immagini o altri file sul metodo Monte Carlo
Wikimedia Commons contiene immagini o altri file sul metodo Monte Carlo
Collegamenti esterni
- (EN) Monte Carlo method, su Enciclopedia Britannica, Encyclopædia Britannica, Inc.

- (EN) Eric W. Weisstein, Metodo Monte Carlo, su MathWorld, Wolfram Research.
- (EN) IUPAC Gold Book, "Monte Carlo (MC), method of", su goldbook.iupac.org.
- https://web.archive.org/web/20060114054216/http://epicws.epm.ornl.gov/rsic.html ORNL Radiation Safety Information Computational Center (RSICC)
- http://www.nea.fr/html/dbprog/ Archiviato il 18 aprile 2006 in Internet Archive. NEA Data Bank Computer Program Services
- Monte Carlo techniques applied in physics, su princeton.edu. URL consultato il 3 maggio 2019 (archiviato dall'url originale il 23 marzo 2012).
- http://homepages.nyu.edu/~sl1544/articles.html Archiviato il 22 giugno 2011 in Internet Archive. Simon Leger, Article on Monte Carlo techniques applied to finance
- http://homepages.nyu.edu/~sl1544/MonteCarloNuls.pdf Simon Leger, Introduction aux techniques de Monte Carlo appliquees a la finance et introduction aux techniques plus avancees.
- http://www.fluka.org/ A particle physics MonteCarlo simulation package
- Chessbase tutorial analisi scacchistica con il Metodo Montecarlo

Software Statistici
- MCMCpack Package R, su cran.r-project.org.
| Controllo di autorità | Thesaurus BNCF 32258 · LCCN (EN) sh85087032 · GND (DE) 4240945-7 · J9U (EN, HE) 987007543534905171 · NDL (EN, JA) 00567842 |
|---|
 Portale Fisica
Portale Fisica Portale Informatica
Portale Informatica Portale Matematica
Portale Matematica








